Configure SQL Server Database Mirroring Using SSMS
Problem
I have a need to setup SQL Server Database Mirroring in my environment. I understand it can be complicated to setup. Can you provide an example on setting up SQL Server Database Mirroring? Check out this tip for a basic look at how to setup this SQL Server feature.
Solution
In this tip I am going to outline my environment and then walk through the process of setting up Database Mirroring. This will include the configurations, backups, restores and verification process. Let's jump in.
My test environment consists of two separate VM's running VM Workstation with Windows 2008 R2 Datacenter Edition and SQL Server 2008 R2 Enterprise named appropriately Principal and Mirror. The SQL Server and SQL Server Agent Services accounts are running as domain users (DOMAIN\User). Windows Firewall is OFF for the sake of this example.
I created a database on the Principal SQL Server instance and named it TestMirror. The recovery model is set to FULL RECOVERY.
1st step: Issue a full backup of the database.
BACKUP DATABASE TestMirror TO DISK = 'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\Backup\Backup.bak';
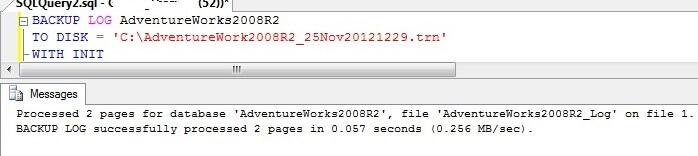
2nd step: Issue a transaction log backup of the database.
BACKUP LOG TestMirror TO DISK = 'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\Backup\Backup.trn';
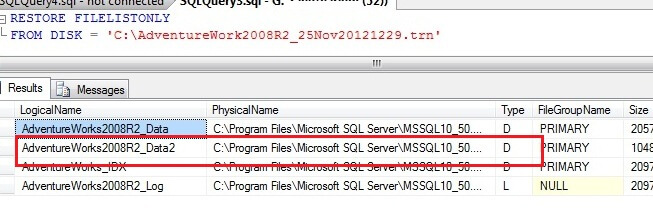
Below are the two files in the file system:
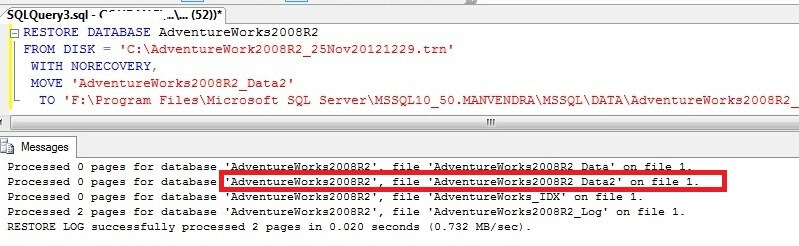
3rd step: Assuming you have the backup folder shared on the Principal Server and you can access it from the Mirror Server, you will need to restore the full backup to the Mirror server with the NORECOVERY option.
RESTORE DATABASE TestMirror FROM DISK = N'\\Principal\Backup\Backup.bak' WITH FILE = 1, MOVE N'TestMirror_log' TO N'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\TestMirror_1.ldf', NORECOVERY, NOUNLOAD, STATS = 10;
4th step: Restore log backup also with the NORECOVERY option.
RESTORE LOG TestMirror FROM DISK = N'\\Principal\Backup\Backup.trn' WITH FILE = 1, NORECOVERY, NOUNLOAD, STATS = 10;
Now it's time to dig down and configure Database Mirroring. From the Principal server, right click the database and choose "Tasks" | "Mirror" or choose "Properties" | "Mirroring".
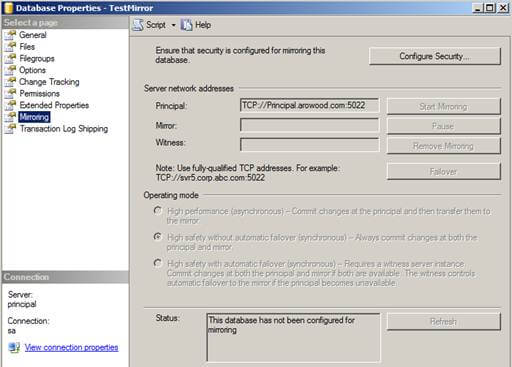
Click the "Configure Security" button and click "Next >" if the Configure Database Mirroring Security Wizard intro screen appears. The next screen should be the Include Witness Server screen:
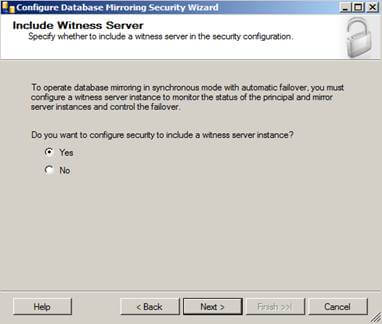
This is where you would configure a witness server for your mirroring, but since we're just configuring a basic mirror we will skip this part. However, if you are configuring mirroring in an Enterprise environment it is recommended you configure a witness server because without one you will not have synchronous automatic failover option.
Select "No", then click "Next >" to continue the process.
The next screen will give you options to configure the Principal Server Instance:
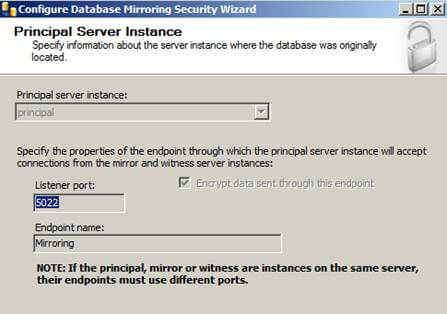
Here we will be creating our endpoint, which is a SQL Server object that allows SQL Server to communicate over the network. We will name it Mirroring with a Listener Port of 5022.
Click the "Next >" button to continue.
The next screen will give you options to configure the Mirror Server Instance:
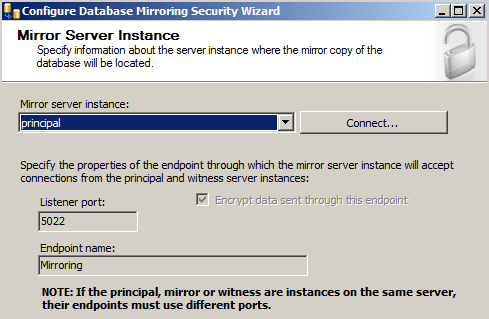
To connect to the Mirror server instance we will need to click the "Connect..." button then select the mirror server and provide the correct credentials:
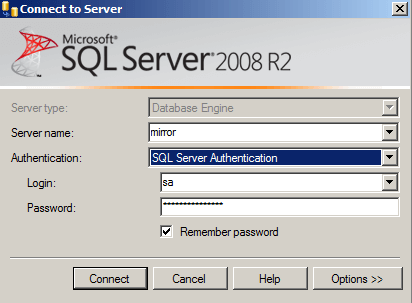
Once connected, we also notice our endpoint name is Mirroring and we are listening on port 5022.
Click "Next >" and you'll see the Service Accounts screen.
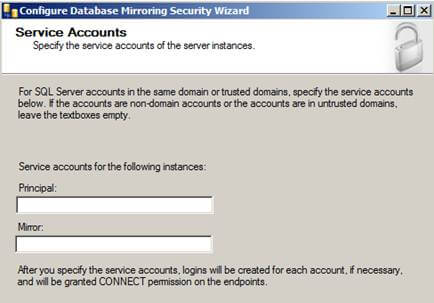
When using Windows Authentication, if the server instances use different accounts, specify the service accounts for SQL Server. These service accounts must all be domain accounts (in the same or trusted domains).
If all the server instances use the same domain account or use certificate-based authentication, leave the fields blank.
Since my service accounts are using the same domain account, I'll leave this blank.
Click "Finish" and you'll see a Complete the Wizard screen that summarizes what we just configured. Click "Finish" one more time.
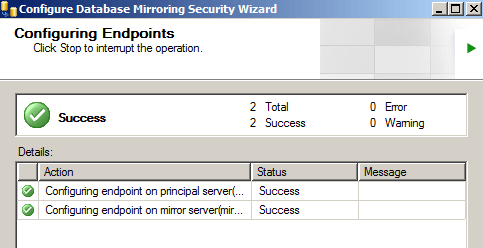
If you see the big green check mark that means Database Mirroring has been configured correctly. However, just because it is configured correctly doesn't mean that database mirroring is going to start...
Next screen that pops up should be the Start/Do Not Start Mirroring screen:
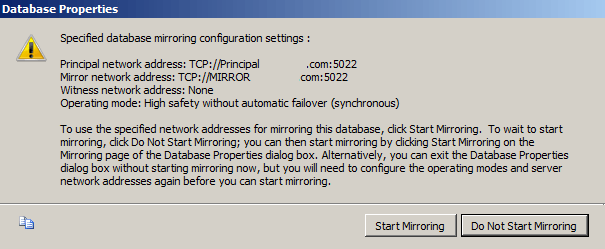
We're going to click Do Not Start Mirroring just so we can look at the Operating Modes we can use:
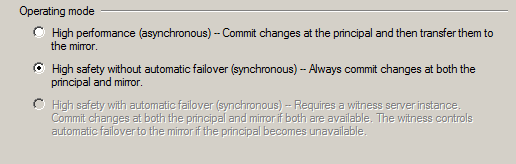
Since we didn't specify a witness server we will not get the High Safety with automatic failover option, but we still get the High Performance and High Safety without automatic failover options.
For this example, we'll stick with synchronous high safety without automatic failover so changes on both servers will be synchronized.
Next, click "Start Mirroring" as shown below.
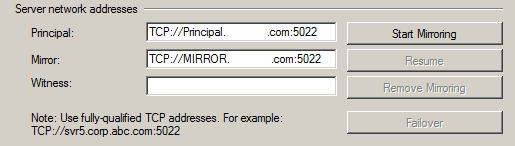
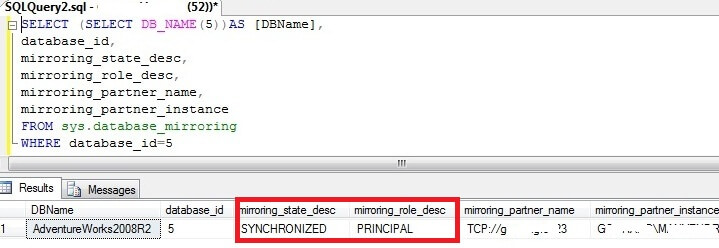
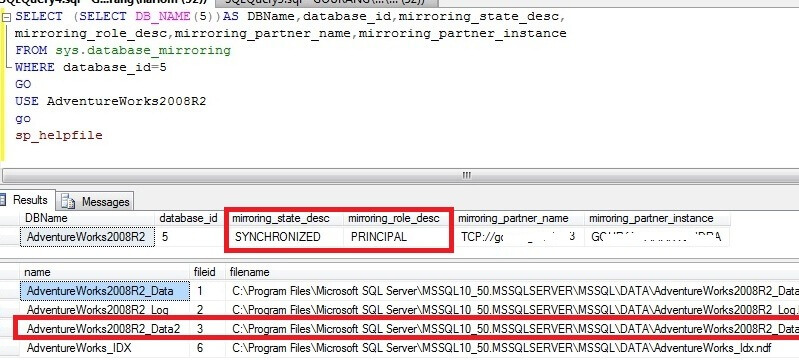
If everything turned out right, Database Mirroring has been started successfully and we are fully synchronized.

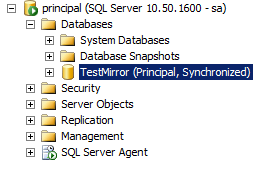
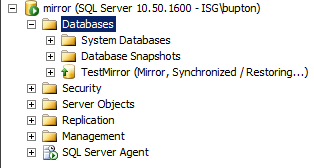
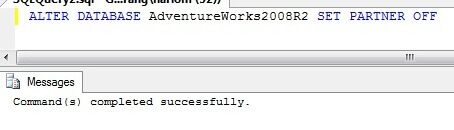
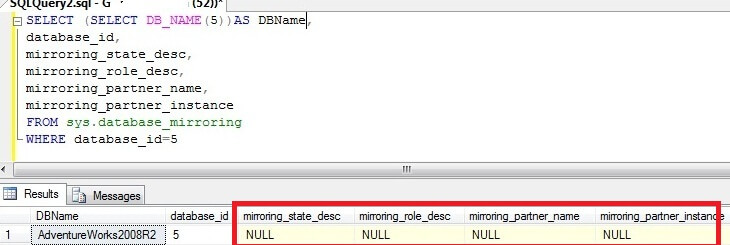
If Database mirroring did not start successfully or you received an error here are a few scripts to troubleshoot the situation:
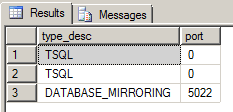
Both servers should be listening on the same port. To verify this, run the following command:
SELECT type_desc, port FROM sys.tcp_endpoints;
We are listening on port 5022. This should be the same on the Principal and Mirror servers:
Database mirroring should be started on both servers. To verify this, run the following command:
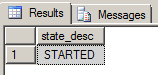
SELECT state_desc FROM sys.database_mirroring_endpoints;
The state_desc column on both the Principal and Mirror server should be started:
To start an Endpoint, run the following:
ALTER ENDPOINTSTATE = STARTED AS TCP (LISTENER_PORT = ) FOR database_mirroring (ROLE = ALL);
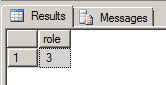
ROLES should be the same on both the Principal and Mirror Server, to verify this run:
SELECT role FROM sys.database_mirroring_endpoints;
To verify the login from the other server has CONNECT permissions run the following:
SELECT EP.name, SP.STATE, CONVERT(nvarchar(38), suser_name(SP.grantor_principal_id)) AS GRANTOR, SP.TYPE AS PERMISSION, CONVERT(nvarchar(46),suser_name(SP.grantee_principal_id)) AS GRANTEE FROM sys.server_permissions SP , sys.endpoints EP WHERE SP.major_id = EP.endpoint_id ORDER BY Permission,grantor, grantee;
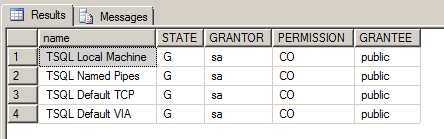
You can see here from the State and Permissions column that the user has been Granted Connect permissions.