Install sequence for Oracle ASM libraries.
While installing, you can install the packages in the below order:
oracleasm-support
oracleasmlib
oracleasm-`uname -r
Please refer to below links:
http://www.oracle.com/technetwork/server-storage/linux/downloading-asmlib-176895.html
http://www.oracle.com/technetwork/server-storage/linux/uln-095759.html
Monday, December 22, 2014
Thursday, December 18, 2014
Oracle Log File Sync Wait Event
Oracle Log File Sync Wait Event
The Oracle “log file sync” wait event is triggered when a user session issues a commit (or a rollback). The user session will signal or post the LGWR to write the log buffer to the redo log file. When the LGWR has finished writing, it will post the user session. The wait is entirely dependent on LGWR to write out the necessary redo blocks and send confirmation of its completion back to the user session. The wait time includes the writing of the log buffer and the post, and is sometimes called “commit latency”.
The P1 parameter in is defined as follows for the log file sync wait event:
Reducing Oracle waits / wait times
If a SQL statement is encountering a significant amount of total time for this event, the average wait time should be examined. If the average wait time is low, but the number of waits is high, then the application might be committing after every row, rather than batching COMMITs. Oracle applications can reduce this wait by committing after “n” rows so there are fewer distinct COMMIT operations. Each commit has to be confirmed to make sure the relevant REDO is on disk. Although commits can be “piggybacked” by Oracle, reducing the overall number of commits by batching transactions can be very beneficial.
If the SQL statement is a SELECT statement, review the Oracle Auditing settings. If Auditing is enabled for SELECT statements, Oracle could be spending time writing and commit data to the AUDIT$ table.
If the average wait time is high, then examine the other log related waits for the session, to see where the session is spending most of its time. If a session continues to wait on the same buffer# then the SEQ# column of V$SESSION_WAIT should increment every second. If not then the local session has a problem with wait event timeouts. If the SEQ# column is incrementing then the blocking process is the LGWR process. Check to see what LGWR is waiting on as it may be stuck.
If the waits are because of slow I/O, then try the following:
- Reduce other I/O activity on the disks containing the redo logs, or use dedicated disks.
- Try to reduce resource contention. Check the number of transactions (commits + rollbacks) each second, from V$SYSSTAT.
- Alternate redo logs on different disks to minimize the effect of the archiver on the log writer.
- Move the redo logs to faster disks or a faster I/O subsystem (for example, switch from RAID 5 to RAID 1).
- Consider using raw devices (or simulated raw devices provided by disk vendors) to speed up the writes.
- See if any activity can safely be done with NOLOGGING / UNRECOVERABLE options in order to reduce the amount of redo being written.
- See if any of the processing can use the COMMIT NOWAIT option (be sure to understand the semantics of this before using it).
- Check the size of the log buffer as it may be so large that LGWR is writing too many blocks at one time.
Log file sync wait event: other considerations
There may be a problem with LGWR’s ability to flush redo out quickly enough if Oracle “log file sync” waits are significant for the entire system. The overall wait time for “log file sync” can be broken down into several components. If the system still shows high “log file sync” wait times after completing the general tuning tips above, break down the total Oracle wait time into the individual components. Then, tune those components that take up the largest amount of time.
The “log file sync” wait event may be broken down into the following components:
1. Wakeup LGWR if idle
2. LGWR gathers the redo to be written and issues the I/O
3. Wait time for the log write I/O to complete
4. LGWR I/O post processing
5. LGWR posting the foreground/user session that the write has completed
6. Foreground/user session wakeup
2. LGWR gathers the redo to be written and issues the I/O
3. Wait time for the log write I/O to complete
4. LGWR I/O post processing
5. LGWR posting the foreground/user session that the write has completed
6. Foreground/user session wakeup
Tune the system based on the “log file sync” component with the most wait time. Steps 2 and 3 are accumulated in the “redo write time” statistic. (i.e. as found under STATISICS section of Statspack) Step 3 is the “log file parallel write” wait event. (See Metalink Note 34583.1:”log file parallel write”) Steps 5 and 6 may become very significant as the system load increases. This is because even after the foreground has been posted it may take some time for the OS to schedule it to run.
Data Guard note
If Data Guard with synchronous transport and commit WAIT defaults is used, the above tuning steps will still apply. However step 3 will also include the network write time and the redo write to the standby redo logs. The “log file sync” wait event and how it applies to Data Guard is explained in detail in the MAA OTN white paper – Note 387174.1:MAA – Data Guard Redo Transport and Network Best Practices.
Final thoughts
When a user session waits on the “log file sync” event, it is actually waiting for the LGWR process to write the log buffer to the redo log file and return confirmation/control back to it. If the total wait time is significant, review the average wait time. If the average wait time is low but the number of waits is high, reduce the number of commits by batching (or committing after “n”) rows.
If slow I/O, investigate the following:
- Reduce contention on existing disks.
- Put log files on faster disks.
- Put alternate redo logs on different disks to minimize the effect archive processes (log files switches).
- Review application design, use NOLOGGING operations where appropriate, and avoid changing more data than required.
If wait times are still significant, review each component of the “log file sync” and tune separately.
Log file sync wait event - demystified
See How Easily you can Solve "Log File Sync" Wait Event ?
Log File Sync - I believe every Database Administrator has seen this wait event during his work. Few can solve log file sync wait Event easily but for other this could be a pain. Before going into how to solve log file sync wait event. Let's understand.
What is Log File Sync Wait Event ?
Whenever user issue a commit statement, LGWR start writing data from log buffer cache to redo log files. Starting from writing to redo log upto get back confirmation from LGWR that data is written in redo log file user session will wait into log file sync wait event. This is basically time when your data is getting written from log buffer to redo log files.
Whenever you see log file sync, I would suggest to take following and analyze.
1. OS Watcher: OS Watcher will give you a fair idea about over all load on the system. Check do you really has high load on system which can cause delay in system I/O process and finally high log file sync wait event. How to Analyze or Read OS Watcher Output in three easy steps ?
2. AWR Report: Next, collect at least two AWR Reports one for good time and another at time of high log file sync wait event. 30 minutes is the good time interval for AWR report, report has longer time interval doesn't help much to figure out root cause of the issue. Database administrator has to compare and Analyze these AWR repots.
3. Alert Log File: Alert log file of database shows how frequently redo logs are switching, recommended time for redo log switching is 15 to 20 minutes if database administrator find that redo log switching is happening more frequently. He should consider resizing redo log files.
How to Solve Log File Sync Wait Event ?
There could be so many reasons for Log file Sync wait event, Here I would explain most obvious reasons from them.
1. Slow Write on Hard Disk: One of the reason for Log file sync wait event could be slow write in to hard disk by LGWR process. To verify this DBA has to compare AVG wait of "log file sync" and "log file parallel write" wait event. Since log file parallel write is a part of log file sync wait event. So DBA has to check if Proportion of log file parallel write is high in log file sync if yes, this issue is due to disk I/O issue. In below AWR report snapshot

Total time wait for Log file sync is 868,667 and out of it 93,144 times it was waiting for log file parallel write wait event which is quite high. One more important criteria to major I/O is If an average time for 'log file parallel write' is over 20 milliseconds this means problem with IO subsystem.
Since you have confirmed the issue is with System I/O. DBA can take following steps to solve this.
1. Check if you are using Hard disk having redo log files for some other files, if yes move redo log files to a separate Hard disk which should not have any frequently accessed data.
2. Do not put redo logs on RAID 5.
3. Ensure that the log_buffer is not too big. A very large log_buffer can have an adverse affect as waits will be longer when flushes occur. When the buffer fills up,it has to write all the data into the redo log file and the LGWR will wait until the last I/O is completed.
4. Ask you network admin to look into and find out root cause of the issue.
2. Excessive Commits from Application: Sometimes Application running on the database also cause high log file wait events due to frequent issue of commit command. Every time user execute commit command LGWR write log buffer data into redo log files which initiate log file sync wait event.
To identify a high commit rate, if the average wait time for 'log file sync' is much higher than the average wait time for 'log file parallel write', then this means that most of the time waiting is not due to waiting for the redo to be written and thus slow IO is not the cause of the problem. The surplus time is CPU activity and is most commonly contention caused by over committing.
DBA can also see, In the AWR or Statspack report, if the average user calls per commit or rollback calculated as "user calls/(user commits+user rollbacks)" is less than 30, then commits are happening too frequently.
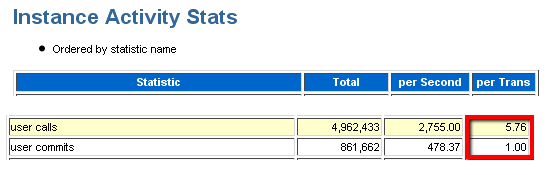
In the above example we see an average of 5.76 user calls per commit which is considered high - about 5x higher that recommended. Rule of thumb, we should expect at least 25 user calls / commit
Recommendations for reducing high Application commits:
1. If there are lots of short duration transactions, see if it is possible to group transactions together so there are fewer distinct COMMIT operations. Since it is mandatory for each commit to receive confirmation that the relevant REDO is on disk.
2. See if any activity can safely be done with NOLOGGING / UNRECOVERABLE options.
3. Talk to development team for making some modifications into application code to reduce high commits.
3. Redo Log file Size: If database redo log file size is not adequate, which cause high number log file switching. During log file switching process LGWR writes all log buffer data into redo log files and goes into log file sync wait event. To verify frequency of log file switching check alert log file which keep record of each log file switch. Recommended time for log file switch is 15 to 20 minutes. If you are seeing frequenct log file switch consider resizing redo log file size.
If you don't find any of the above issue matching your situation. Then there could be some known bugs into the database. I would suggest to open a Service Request with Oracle Support for further assistance.
Subscribe to:
Comments (Atom)